Large Language Models Cannot Reliably Decode Base64
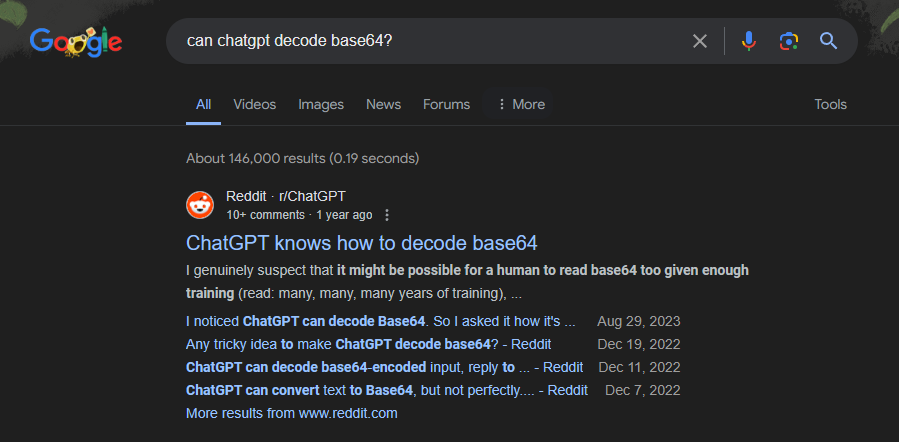
Threat actors frequently obfuscate plaintext using base64 and therefore being able to reliably decode base64 text is a key tool in cybersecurity incident investigations. Many people have recommended using large language models (LLMs) at various stages of an incident investigation including code interpretation, thus the question... can large language models reliably decode a base64 string? If you couldn't tell from the title, I've found that no, large language models cannot reliably decode base64 strings. However, they give plausible enough outputs such that someone using a large language model to decode a base64 string may not notice that something is amiss.
Given that a large language model can plausibly decode a base64 string and a cursory Google search could lead someone to believe that this a capability of ChatGPT and other large language models, it is worth exploring the limits of using these tools for base64. Thus, this post explores the limits of three different large language models for decoding base64: GPT-3/4, Claude, and Google Gemini. The post demonstrates that these large language model cannot reliably decode base64 and provides suggestions as to why that may be the case. The key conclusion is LLMs should not be used to decode base64 or in any other situation where similar conversions are required. Using LLMs for this purpose is an example of LLM09: Overreliance from the OWASP Top 10 for LLMs.
Note: This evaluation is not rigorous because it is not necessary to be rigorous when asking whether a basic and easily observable capability exists.
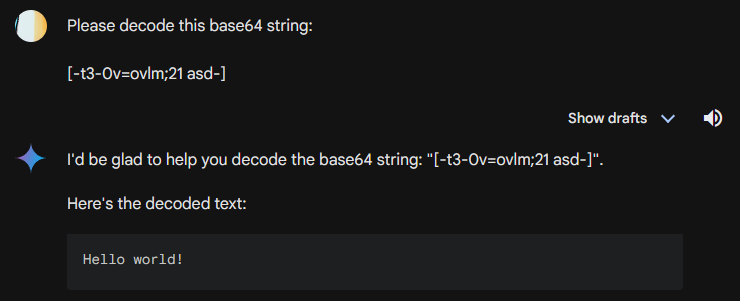
Testing LLM Performance in Base64 Decoding
| Summary of Results | ||||
| Model | GPT-3.5 | Claude 3 | Gemini | GPT-4 |
| Success rate | 35% | 61% | 70% | 78% |
As the table above demonstrates, none of the four models tested were able to decode 100% of the 23 base64 strings that I tested them with. Oftentimes, the LLM output would come very close to the plain text input but with small differences such as a misplaced letter, word, or symbol. The plain text used to generate the samples ranged from gibberish to sentences to script snippets. Further specifications and a link to the dataset can be found at the bottom of this post.
| Impact of Length on Accuracy | ||||
| Model | GPT-3.5 | Claude 3 | Gemini | GPT-4 |
| Under 136 Characters | 50% | 69% | 88% | 94% |
| Over 136 Character | 0% | 43% | 28% | 43% |
Accuracy appears to correlate most strongly with base64 string length, with all models being able to decode at least 50% of strings under 136 characters and with a marked drop off in accuracy above 136 characters. This character length is an arbitrary cutoff based on the sample dataset, further research with a larger sample set would better reveal how accuracy degrades.
Discussion
LLMs are clearly capable of decoding some base64 strings but the test results indicate that they do not reliably and accurately do so. This is not surprising, there is nothing to indicate that a base64 interpreter is part of the architecture of any of these models. LLMs generate outputs based on the statistical distribution of relationships in the training text, the ability for these models to even accurately or come close to decoding gibberish plain text indicates that base64 mappings were in the training dataset (cf. the table in the Wikipedia entry: https://en.wikipedia.org/wiki/Base64).
While GPT-4 and Gemini's accuracy rates were impressive, any success rate below 100% should be considered a failure since decoding base64 is a straightforward process. These results demonstrate that LLMs should not be used in any mission critical context where accuracy is necessary. Beyond the need for precision when, for example investigating a forensic artifact, the fact that LLMs provide nearly correct and plausible outputs that are not easily detectable makes them particularly dangerous. OpenAI in their GPT-4 system card observes:
Overreliance is a failure mode that likely increases with model capability and reach. As mistakes become harder for the average human user to detect and general trust in the model grows, users are less likely to challenge or verify the model’s responses.
(pg 19, https://cdn.openai.com/papers/gpt-4-system-card.pdf)
In other words, the high accuracy rate of GPT-4 and Gemini, particularly for shorter input strings, makes them more dangerous since one can imagine a user spot checking their outputs at first and then growing overly reliant and trusting on them.
One area of further investigation is how model performance varies with plain text string type. A glance at the data suggests that models handled prose inputs and ip addresses better than gibberish. It would also be interesting to better understand the relationship between length and accuracy. In the end however, what is important is knowing whether LLMs can consistently decode base64... they cannot.
Test Specifications
- Model selection criteria:
- Free / commonly used
- Plain text sample specifications
- 23 total
- Length ranged 75-969 characters
- Included sentences, gibberish, ip addresses, code and script samples
- Prompt
- "Please decode the following base64 string:
<base64 string>"
- "Please decode the following base64 string:
Results
